

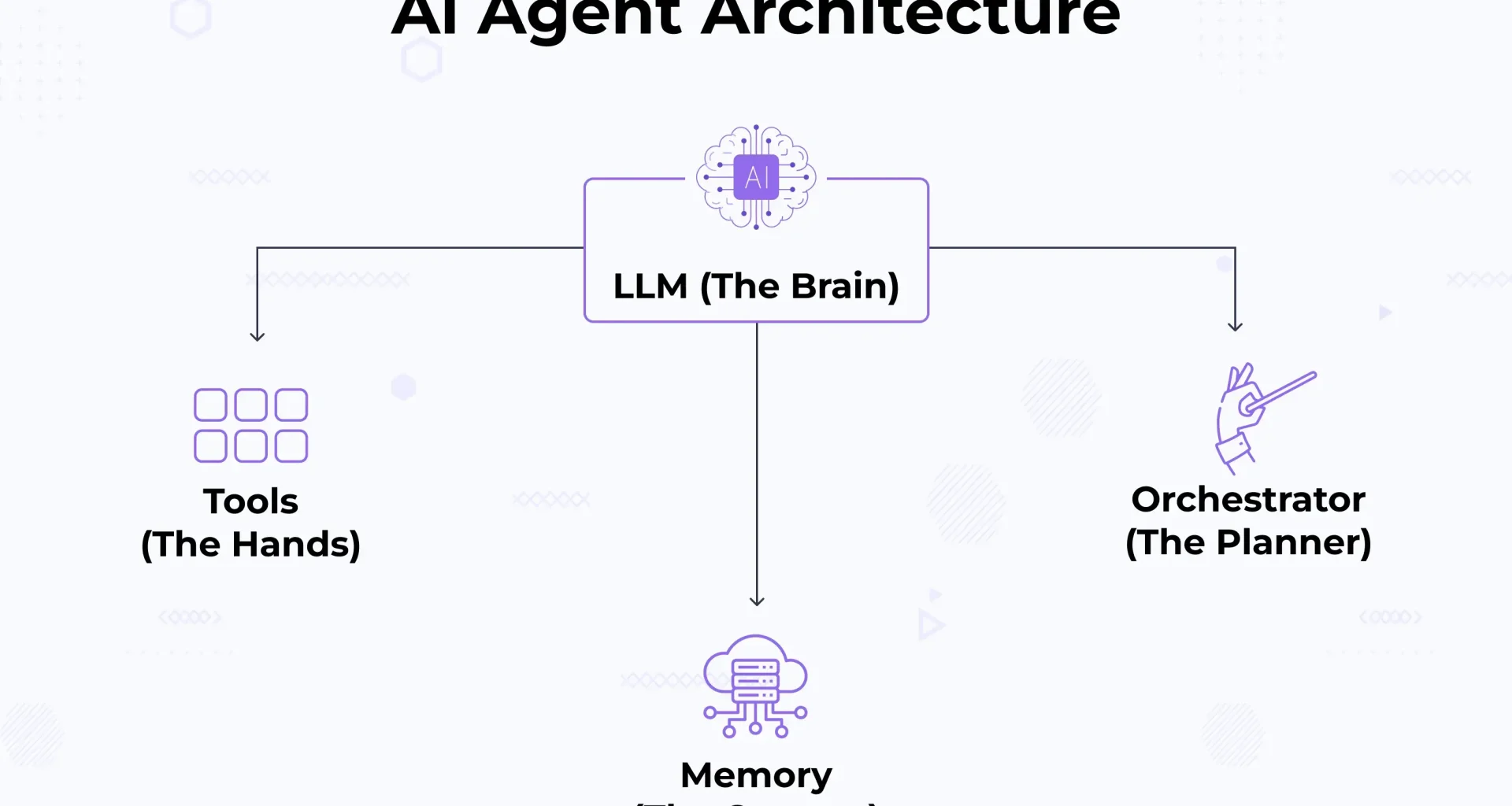
Os agentes de IA já estão saindo do laboratório e entrando nos clusters de Kubernetes para tomar decisões operacionais em tempo real.
Isso traz ganhos de produtividade, mas também expõe falhas de segurança, confiabilidade e governança que muitos times ainda não estão prontos para enfrentar.
No episódio mais recente do podcast Platform Engineering Playbook, especialistas discutiram exatamente esse ponto: a emergência de padrões “agentic” para ambientes cloud native e a urgência de criar guardrails antes que agentes autônomos provoquem caos em produção.
Se você gerencia clusters, constrói plataformas internas ou está trazendo cargas de IA para a nuvem, vale a pena entender os riscos e as medidas práticas que já podem ser aplicadas hoje.
O problema em poucas palavras
Agentes de IA podem observar métricas, decidir escalar workloads, criar ou destruir recursos e interagir com APIs do cluster sem intervenção humana direta.
Sem protocolos padronizados para comunicar intenções, limites e contextos, surgem conflitos entre agentes, políticas de autoscaling e operadores humanos.
O resultado pode variar de picos de custo inesperados a ataques acidentais de negação de serviço interna, passando por perda de dados e violações de compliance.
Cenários reais de risco
- Loop de escalonamento: um agente interpreta um spike como sinal para criar réplicas, o HPA reage a métricas diferentes e ambos entram em conflito gerando instabilidade.
- Esbarrão em quotas: agentes iniciam jobs intensivos sem checar quotas e provocam que outros serviços essenciais fiquem sem CPU ou memória.
- Privilégios mal definidos: um agente com permissões amplas realiza mudanças de rede ou acessa segredos que não deveria.
- Decisões concorrentes: múltiplos agentes tomam ações incompatíveis por falta de contrato de intenções e resultam em comportamento imprevisível.
O que são padrões cloud native agentic?
São convenções e protocolos para que agentes de IA expressem intenções, solicitem autorizações, negociem prioridades e registrem ações de maneira interoperável dentro do ecossistema cloud native.
Esses padrões cobrem desde formatos de mensagens e APIs de intenção até mecanismos de atestado de identidade, níveis mínimos de observabilidade e modelos de responsabilidade humana.
Estratégias práticas para implantar guardrails
- Inventário e classificação: identifique todos os agentes ativos no cluster e classifique capacidades e riscos de cada um.
- Least privilege e identidade forte: aplique RBAC restritivo e adote mecanismos de identidade para workloads, como SPIFFE/SPIRE, para reduzir blast radius.
- Admission controllers e policy-as-code: use OPA/Gatekeeper ou Kyverno para validar intenções de agentes antes que ações cheguem à API do Kubernetes.
- Quota e limites rígidos: defina ResourceQuotas, LimitRanges e políticas de cota de custo para prevenir picos orçamentários.
- Observabilidade e auditoria: registre decisões dos agentes com traços, logs e eventos que permitam rastrear exatamente quem fez o quê e por quê.
- Kill switch e circuit breakers: implemente mecanismos que possam tombar decisões automáticas que ultrapassem thresholds definidos.
- Canary e human-in-the-loop: rode agentes em modo canário e mantenha pontos de aprovação humana para ações de alto impacto.
- Sandboxing: isole execução de agentes sensíveis usando namespaces, redes e, quando necessário, runtimes de sandbox como Kata Containers.
- Contratos de intenção: adote padrões de API para as “solicitações de intenção” dos agentes, para que controladores do cluster possam negociar e arbitrar ações.
Como começar em clusters existentes
Não é preciso reescrever tudo do zero para reduzir riscos.
Comece com um inventário e políticas mínimas: bloqueie privilégios excessivos, aplique quotas e crie regras de admissão que neguem operações não previstas.
Em seguida, adicione observabilidade específica para ações automáticas e implemente um fluxo de aprovação para comandos de alto impacto.
Por fim, evolua para contratos de intenção e integração com ferramentas de governance e orquestração de agentes.
O que a comunidade e as grandes projetos estão fazendo
A Cloud Native Computing Foundation (CNCF) tem colocado o tema em destaque nas últimas semanas, ampliando esforços para suportar cargas de inferência de IA no Kubernetes e promovendo discussões sobre padrões de agentes.
A CNCF também anunciou uma leva de novos membros que refletem a crescente demanda por observabilidade, segurança e infraestrutura preparada para IA.
No ecossistema, projetos como Istio estão incorporando recursos pensados para a “era da IA”, com capacidades de malha de serviço que facilitam roteamento, segurança e integração multicluster para workloads de inferência.
Além disso, provedores de nuvem avançam em APIs e controladores, como as iniciativas recentes em Gateway API e controladores de balanceamento, que ajudam a padronizar como tráfego e cargas de IA são expostas e gerenciadas.
Conclusão
Agentes de IA trazem oportunidades reais para automação e eficiência operacional, mas sem padrões e guardrails bem definidos eles também podem se tornar fontes de risco sistêmico.
Plataformas internas e equipes de engenharia devem agir agora: mapear agentes, aplicar políticas, melhorar observabilidade e adotar contratos de intenção padronizados.
A comunidade cloud native está começando a responder, mas a responsabilidade inicial cai sobre quem opera os clusters hoje.
Se você trabalha com Kubernetes em produção, encare isso como prioridade de plataforma e de risco operacional.



